📖缓存|Redis
2024-8-18|2024-11-14
黎明
type
status
date
slug
summary
tags
category
icon
password
进度
发布历史俗语下载高性能分析SDSZipListLinkListHash TableIntSetSkipTable内存淘汰策略分布式锁事务消息队列集群面试问题:跳表 VS 平衡树面试问题:缓存穿透 缓存雪崩 缓存击穿参考文章
发布历史
俗语
- 客户端缓存 Client Side Caching
- 简单动态字符串 SDS Simple Dynamic String
- 缓冲区溢出 Buffer Overflow
- 双向列表 Dually linked list
- 大端 Big Endian (BE)
- 小端 Little Endian (LE)
- 冲突 Collision
- 柔性数组 Flexible array member
- 高可用 High Availability
- 高性能 High Performance
- 平均修复时间 Mean time to repair,MTTR
- 复原时间目标 Recovery Time Objective,RTO
下载
高性能分析

- 内存存储:访问速度是固态磁盘1千倍,是机械磁盘1万倍
- I/O模型:多路复用模型,非阻塞的I/O模型
- 单个线程:避免上下文切换和竞选
- 高效数据结构: 根据业务数据选择底层恰当数据结构,提高效率

性能评测: 在较高配置基准(8C 16G),在60000连接下,保持50000q/s 超高性能。
SDS
sds.h, sds.c
- len: 表示字符串长度
- free: 表示空闲长度
- buf: 表示数据内容
注意:sizeof(sdshdr)=8Byte,若存储小字符串,则浪费较多空间。
优化:按照内容长度选择合适大小结构。
sdshdr5 | sdshdr8 | sdshdr16 | sdshdr32 | sdshdr64 |
2^5 | 2^8 | 2^16 | 2^32 | 2^64 |
高5位 | ㅤ | ㅤ | ㅤ | ㅤ |
- 长度时间复杂度
- 防止缓存区溢出
- 减少内存重分配次数
- 存储二进制数据
字符串增加导致扩容(空间预分配)
sds.c
redis
SDS_MAX_PREALLOC: 1024 * 1024 (1MB)
- avail >= addlen: 剩余存储空间足够,无须扩容
- newlen < SDS_MAX_PREALLOC:按照1倍扩容
- newlen ≥ SDS_MAX_PREALLOC:按照1MB扩容
- s_malloc更换header。sdshdr5→sdshdr8→sdshdr16→sdshdr32→sdshdr64
字符串减少或者删除导致所容(惰性空间释放)
sds.c
redis
ZipList
ziplist.c
redis
zlbytes | zltail | zllen | entry | …… | entry | zlend |
4B | 4B | 2B | 变长 | 变长 | 变长 | 1B=FF |
- zlbytes : 占用字节数,调整大小
- zltail : 最后一个entry的偏移量,允许在另一端pop
- zlen : 时表示entry数量;时需要遍历
- zlend : 结束符
prevlen | encoding | entry-data |
1B or 5B | 1B~9B | ㅤ |
- prevlen : < 0xfe占用1B表示长度; =0xfe占用5B,____使用4B表示长度
- encoding : 根据第一个字节的设计的编码方式有关系
编码方式 | 长度 | 范围 |
|00pppppp| | 1B(6bit) 字符串 | 2^6 - 1 |
|01pppppp|qqqqqqqq| | 2B(14bit) 字符串 | 2^14 - 1 |
|10000000|…|…|…|…| | 5B (32bit) 字符串 | 2^32 - 1 |
|11000000|…|…| | 3B (16bit) 整形 uint16 | ㅤ |
|11010000|…|…|…|…| | 5B (32bit) 整形 uint32 | ㅤ |
|11100000|…|…………|……| | 9B (64bit) 整形 uint64 | ㅤ |
|11110000|…|…|…| | 4B (24bit) 整形 uint24 | ㅤ |
|11111110|…| | 2B (8bit) 整形 uint8 | ㅤ |
|1111xxxx| | 1B (4bit) [1,13] | 0000 < xxxx < 1110 |
LinkList

快速列表quicklist
quicklist.h
redis

混合模式:
quicklist = linkedlist + ziplist
优点:
- 插入、删除时间复杂度
- 内存使用率提高
缺点:
- 引入ziplist, 可能引起连锁更新等问题
- 遍历时间复杂度
约束:
- 内部默认单个ziplist长度8KB
- 配置文件:list-max-ziplist-size 控制ziplist长度
Hash Table
经典哈希表:哈希函数→哈希冲突→链式哈希

记:
哈希表固定长度:m
哈希存储对象数量:n

则:
装载因子

当足够大时:
- 链表越来越长
- 插入、删除性能下降

Redis哈希表

若保持性能,则需要扩容。
- 哈希表特殊性,长度增加时,存量数据key
重新哈希计算。


IntSet

- encoding: 根据数据类型调整
INTSET_ENC_INT16 | 2字节 |
INTSET_ENC_INT32 | 4字节 |
INTSET_ENC_INT64 | 8字节 |
- length: 长度
- contents: 数据;连续内存


SkipTable



在有序列表上增加多集索引。
- 查询类似二分查找,效率
- 插入、删除
- 插入新节点数据,可能破坏上下层级比例,若要维持这种比例,则重新调整,导致时间复杂度退化成
- 优化:每个节点有一个level属性,是随机生成的,而且新插入一个节点不会影响其它节点的层数。

内存淘汰策略
约束:物理机器内存总归有限,不可无限使用。而在使用过程中,有可能出现内存消耗超过内存实际大小。
未设置过期时间 | 一直存在直到明确删除 |
不合理持久化 | RDB/AOF 在内存和磁盘反复操作,消耗内存处理 |
不及时清理过期 | 主动清理:默认100m定时执行一次,每次抽取设置过期时间的key(1/4)
被动清理:查询时过期检查,若过期则删除 |
不合理使用 | 同时缓存热数据和冷数据导致内存占用过多
缓存数量或者单个缓存数据体积过大
缓存时间设置太长或者不设置 |
redis.conf
策略 | 含义 |
noeviction | 不淘汰;当内存超过阈值则创建失败 |
volatile-lru | 设置过期时间的key; LRU |
volatile-lfu 4.0 | 设置过期时间的key; LFU |
volatile-random | 设置过期时间的key; 随机删除 |
volatile-ttl | 设置过期时间的key; 过期时间身剩余最少 |
allkeys-lru | 所有key; LRU |
allkeys-lfu | 所有key; LFU |
allkeys-random | 所有key; 随机 |
分布式锁
定义:分布式系统中的锁,通过锁控制共享资源的访问;
- 互斥性
- 安全性
- 过期性
- 高性能
: set if not exists; 若不存在则创建,若存在则不做操作。
锁作唯一标识
事务
阶段:开始事务、命令入队、执行事务
- redis事务无隔离级别,在exec发送前,命令暂放到队列缓存中,并不会实际执行。
- redis事务不保证原子性
消息队列

- 解耦(订阅发布,异步处理)
- 有序性
- 消息路由
- 削峰
Broker | 消息服务器 | 包含多个Q |
Producer | 消息生产者 | msg → broker.Q |
Consumer | 消息消费者 | broker.Q → msg |
采用List实现方式面对的问题:
- 消费及时性问题;
- 方案一: 通过RPOP轮训,占用网络IO和CPU
- 方案二:阻塞等待 BRPOP,无数据时阻塞读取,有数据时返回数据。
- 消费重复性问题:
- 业务生成全局标识,消费者幂等检查
- 消息可靠性问题:
- 消息读取时缺少ACK机制,若发生崩溃则会遗漏消息。RPOPLPUSH读取备份。
(Redis 5.0) Stream
- 每个Stream创建时都会有唯一标识(key)
- 支持多个消费组
- 支持消息确认机制

- 消费组间是竞争关系
- pending_ids[]表示已读取未确认
- megId: 毫米+序列

XCLAIM | 转移消息归属权 |
XACK | 确认消息 |
XINFO | 查询流和消费组信息 |
集群
- 高可用:遇到不可预见问题时仍然正常运行。比如硬件故障、网络故障
- 冗余:避免单点故障
- 自动故障转移
- 负载均衡
- 数据备份与恢复
- 心跳检查
- 高性能:关注服务的响应时间、处理能力和整体效率
- 缓存
- 并行处理
- 缩减延迟
- 非阻塞IO
- 垂直扩展和水平扩展
针对不同场景提供高可用和高性能的解决方案:
主从模式:
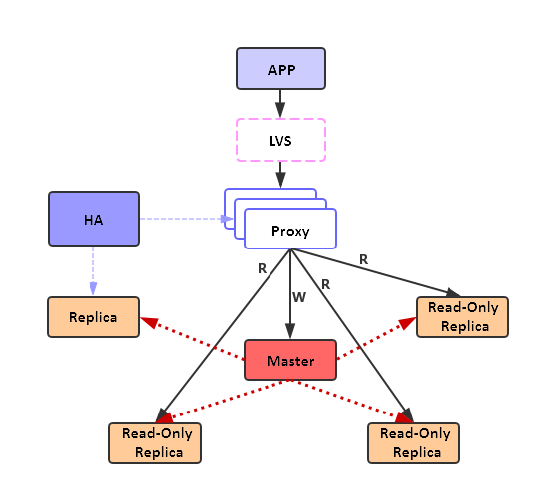
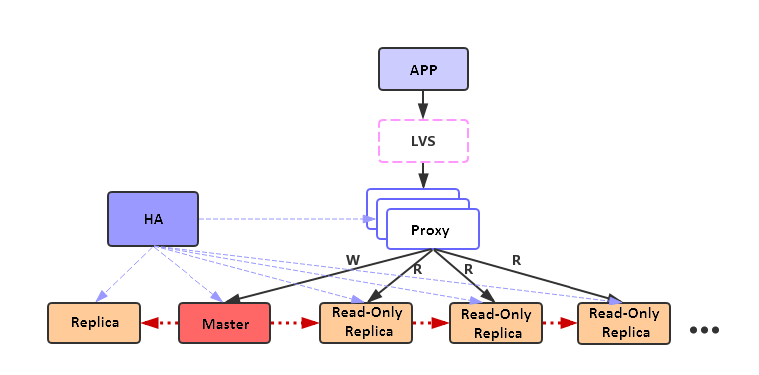
- 读写分离
- 应用层通过逻辑控制读、写操作
- 代理中间件,根据请求类型路由到实例
- Twemproxy
- Codis
- 同步机制
主库配置:
从库配置:
缺点:
- 不具备自动容错和恢复功能
- 主从宕机影响部分请求失败,需要重启或手动切换IP
- 数据丢失
- 数据未分片,无法在线扩容
哨兵模式

下线标记
- 每秒心跳检查,若无响应则tag标记下线状态offine
故障转移
- 哨兵心跳检查主节点,超时不响应标记主观下线。+sdown
超时配置:down-after-milliseconds
- 哨兵发送指令:sentinel is-master-down-by-address-port 其他哨兵订阅消息
- 其他哨兵也对master心跳检查重复(1)(2)
- 汇总计票,票数超过半数,判定客观下线。+odown
超过配置:quorum(注意脑裂)
- 主节点odown将重新选举master
- 指定哨兵选举:规则如下
- 响应快:Sentinel→Slaves 通信
- 差距小:offset越新越好
- RunId小:越早表示创建越早
- 切换master

- 广播通知slaves切换master
replacaof ip port
- 新主节点地址通知给客户端
新增功能点:参考文章
- 集群监控
- 心跳检查
- 自动故障转移
- 竞选机制
- 故障检测与通知
- 配置更新与通知
哨兵和主从间通信
哨兵间通信 pub/sub
- master有一个__sentinel__:hello专用通道
- sentinel发布<name> <ip> <port>信息
- sentinel订阅其他sentinel信息
- sentinel建立通

集群模式 参考文章

- 直接创建,均匀分配哈希槽
- CLUSTER MEET <ip> <port>
优点:
- 千万级甚至亿级别的流量
- 具备哨兵模式优点
- 客户端能够快捷的连接到服务端
缺点:
- 批量操作不支持,由于数据分布式存储
- 无法将冷、热数据隔离
- 从节点充当“冷备”,无法分摊读操作
Redis Cluster是一种分布式数据库方案,集群通过分片模式来对数据进行管理。
- 哈希槽
- 集群间通过Gossip协议通信
客户端连接:
- 客户端连接任一节点,获取slots与节点关系并缓存本地
- slot = crc16(key) % 16384
- 通过(1)找到对应<ip><port>

优化:
- 避免产生hot-key,导致主节点成为系统瓶颈
- 避免产生big-key,导致慢查
面试问题:跳表 VS 平衡树

- 内存占用
- 范围查询
- 实现复杂度
面试问题:缓存穿透 缓存雪崩 缓存击穿
缓存穿透:数据既不在缓存中也不在数据库中,导致每次请求穿透到数据库,放大数据库压力。
解决:不合法或者不存在的数据尽早拦截,比如通过布隆过滤器过滤不存在数据。
缓存击穿:单一热点数据失效
解决:
- 热点数据不设置过期时间或设置长过期时间;过期时间 = 设定时间➕随机时间
- 预热热点数据
- 缓存失效时
- 先过去分布式锁
- 抢锁成功后请求数据库,抢锁失败后等待
- 查询数据库后构建缓存
缓存雪崩:大量热点数据同时过期,或者缓存服务宕机
解决:
- 热点数据不设置过期时间或设置长过期时间;过期时间 = 设定时间➕随机时间
- 接口限流,利用队列削峰
- 服务熔断,缓存获取失败直接错误返回
参考文章
Loading...
- 关于

黎明
当机器会思考时,会不会失业?!
博客 已经上线🎉
但行耕耘,不问收获 🤪
-- 感谢您的支持 ---